Book a Free Call
No commitment required
The acronym stands for Application Performance Monitoring (and also Application Performance Management, but we will only focus on the first one) and it refers to the monitoring of telemetry data to measure our system’s health, and availability, or even to troubleshoot problems while it is online.
APM is a means to increase the observability aspect of our system, allowing us to know about its internal state by reading through its external output. Now, before we dive deeper, let’s briefly go over some concepts that were just called out to ease the understanding of this subject.
When we mention Telemetry Data we’re referring to the information that’s emitted by our systems in the shape of logs, metrics, and traces.
Logs are timestamped messages or text records with some metadata. They’re generally used to describe things that occur while our application is running.
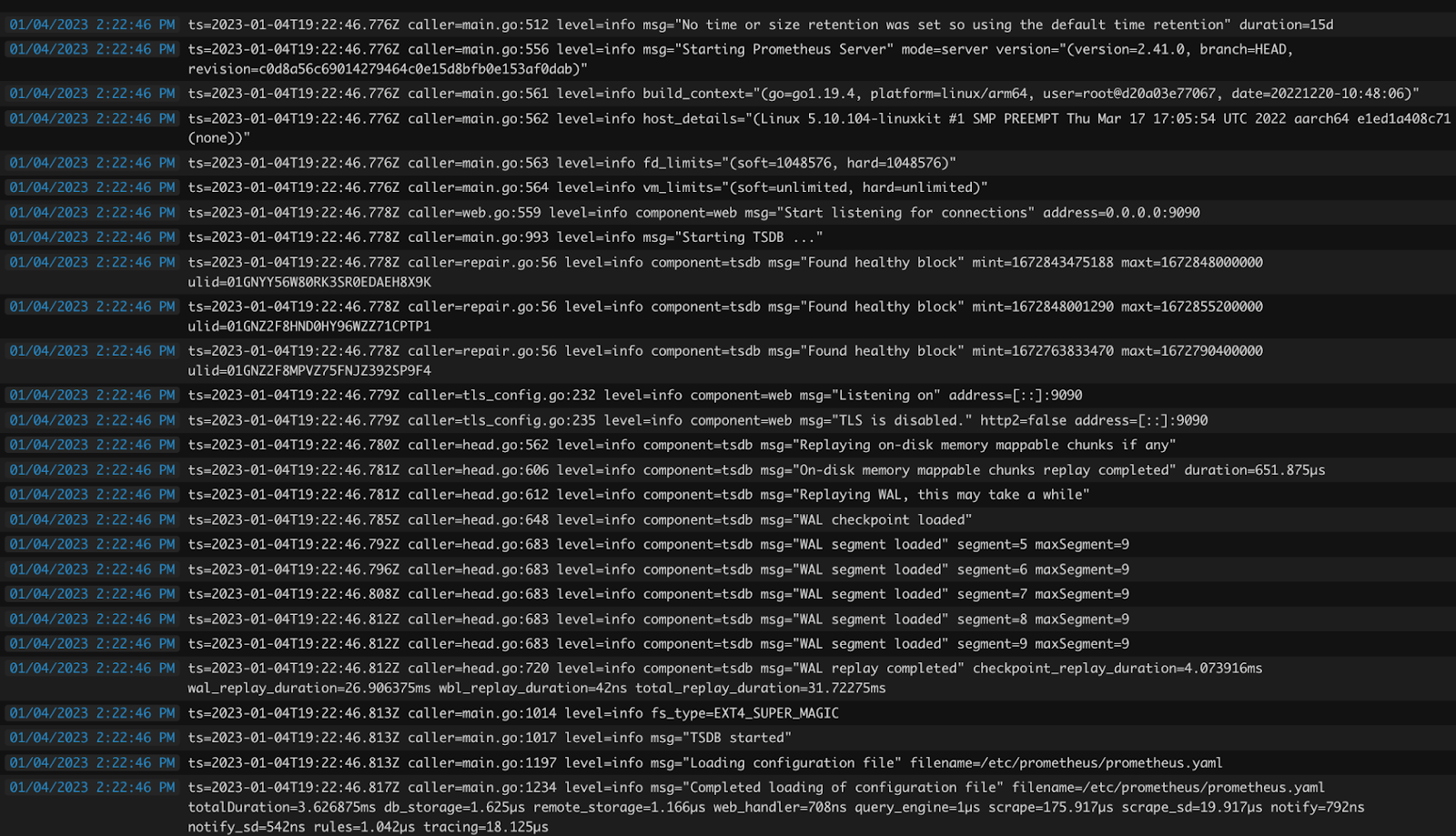
Metrics are measurements of our applications that are gathered at Runtime. They are a great indicator of our system’s performance and availability. Generally speaking, this kind of telemetry data is used for setting up alerts when certain thresholds in our application are surpassed(e.g Memory usage, CPU Usage, and so on)
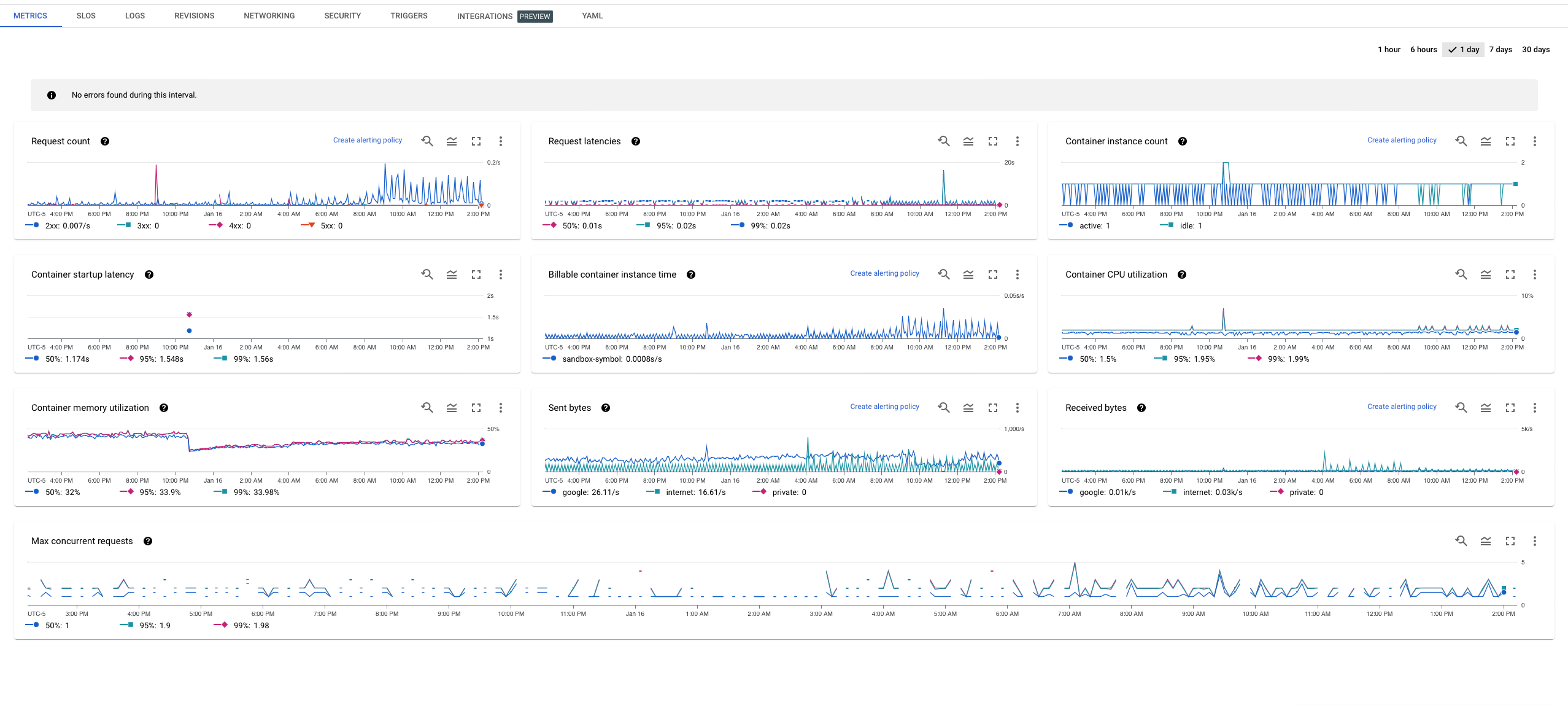
Refers to the aspect of systems that allow us to know about their internal state by looking at their external output. Although, it is worth mentioning that Observability is also referred to as an evolution of APM for more complex cloud-native applications whose volume of telemetry data is significantly larger than monolithic applications.
Now that we’ve briefly gone through those concepts, let’s get back to the subject in question.
The importance of APM lies in its ability to make our system’s performance more visible as a whole. This means, if we have our system properly instrumented, we’re able to pay attention to specific aspects of it that allow us to provide a better user experience in general. In some cases, this allows us to be ahead of the possible issues that may occur based on the behavior we see.
APM tools also include alert configurations that notify the team under certain circumstances, which allows us to focus on the most relevant indicators of our system that we need to provide the best experience to end users and guarantee a desired uptime.
Proper monitoring of our systems helps us identify the root cause of an issue, which enables us to promptly act upon that. This swiftness can make our product more competitive overall.
In a production scenario, the longer the problem takes to resolve, the more frustrating it becomes to the people that use it, which may lead them to consider other alternatives to our product.
But that’s only one side of the coin, on the other hand, we have the impact that the issue will cause on the development team in charge of the system. They may have already plans for the work they’re planning to ship next, but some of it might be delayed depending on the priority of the issue at hand. So the next thing that would need to be done is to replicate the symptoms of the issue in order to determine the root cause of the problem.
This vermin hunt that the dev team will go through might not succeed every time because they might end up reproducing the same problem but under a different root cause.
The takeaway is that we can’t fix a problem unless we find its exact root cause. If we don’t know it, any solution we try to implement will be a shot in the dark.
In this context, we can’t improve something we don’t measure. Having metrics of the resource consumption of our systems can open the door for future enhancements to the cost its currently takes us to keep them up and running. Apart from that, it can also provide visibility over possible bottlenecks in our system (traces), in most cases before they become a problem for the users.
Application performance monitoring is not a mandatory aspect to cover while building our applications, but making our systems observable by instrumenting them to be measured, can be beneficial for their success and survivability.
In a future post, we will be diving deeper into the instrumentation of a Go web app to see those APM concepts in action. Stay tuned!