Book a Free Call
No commitment required

Organizations use data for a variety of purposes, such as understanding customer trends, detecting issues, identifying new opportunities, and tracking operational results. Effective data management and analysis are very important because they enable companies to make strategic decisions, optimize processes, and maintain a competitive edge[1]. Relational database management systems (RDBMS) facilitate this capability, with SQL being the fundamental language for interacting and communicating with databases.
When faced with requirements of creation of a new report or resolution of an issue, the instinct might be to turn to complex coding solutions. However, often, elegant and effective solutions can be crafted directly within the database.
In this blog post, you will explore SQL’s history, fundamentals, and features. Additionally, you will discover real-world scenarios that without being overly complex, will provide insight into the power of SQL, and demonstrate the issues that can be solved using it.
Structured Query Language, SQL for short, is a programming language for storing, retrieving, and manipulating data in database management systems such as Oracle, MySQL, Microsoft SQL Server, PostgreSQL, SQLite, or MariaDB[2].
SQL has evolved significantly since its creation in the 1970s by IBM researchers Raymond Boyce and Donald Chamberlin. Today it is widely used in software development, in fact, SQL was ranked by StackOverflow in 2024 as the third most admired and desired programming language.[3]
In the early 1970s, Edgar F. Codd proposed a new way to structure data, what is known as the relational model. Later IBM, started a project called System R, which aimed to create a prototype database system based on Codd’s relational model. During the development of that system, Donald D. Chamberlin and Raymond F. Boyce developed a structured query language called SEQUEL to interact with the System R; Patricia Selinger developed a cost-based optimizer that made relational databases more efficient; Raymond Lorie invented a compiler that could save database query plans for later use. Subsequently, Relational Software (now Oracle) introduced one of the first commercial implementations of SQL.[4]
Let’s delve into its fundamental concepts.
SQL allows a wide range of operations, such as querying data, updating records, inserting new data, and deleting data. These operations are performed using specific commands, which can be categorized into 4 types:
DDL commands are used to create a database, modify its structure, and destroy database objects when no longer needed.
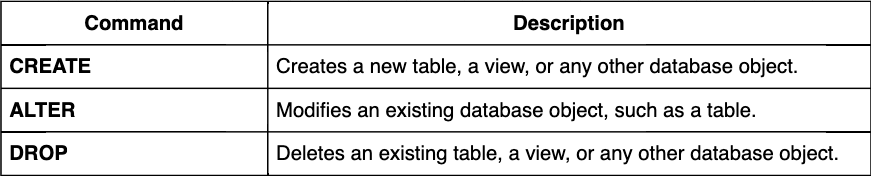
DML commands allow users to retrieve, add, modify, and delete data within a database.

DCL commands are used to manage access permissions and security settings. These commands are used to protect the database from being corrupted. The degree of protection depends on the implementation.

TCL commands help to manage database transactions, ensuring data integrity. These enable the control of changes made by DML statements and allow the grouping of statements into logical transactions.

Having reviewed the core SQL commands, let’s dive into key clauses and features that help you tackle common challenges and troubleshoot effectively.
Before moving forward, let’s define the structure of the database that we’ll use to demonstrate the scenarios.
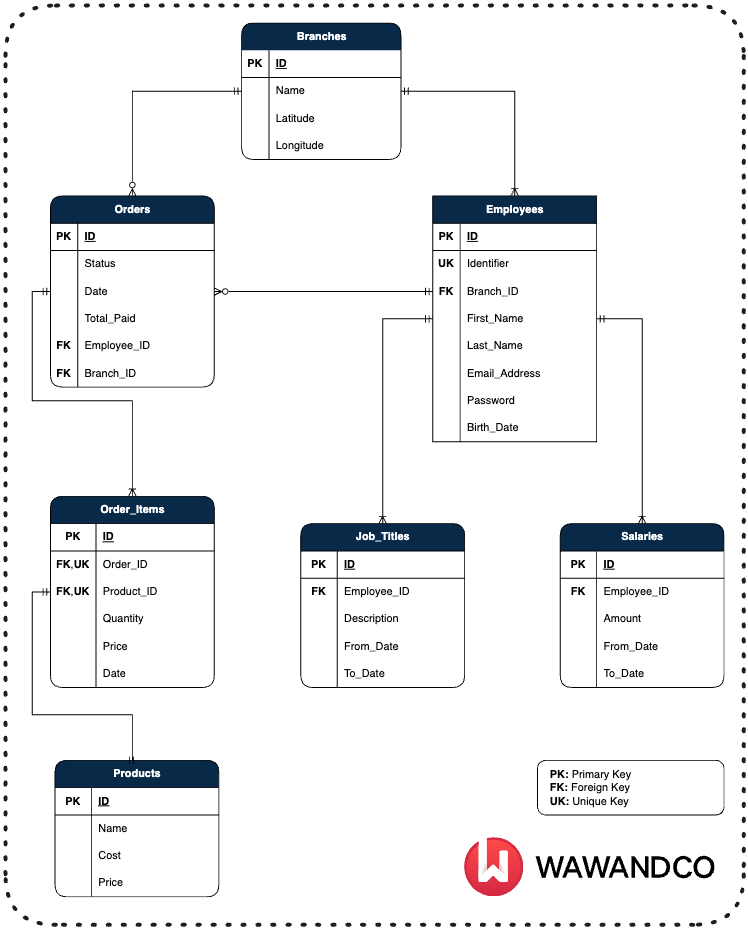
A view is a virtual table that displays data based on the result set of a SELECT query that runs on one or more tables. Views help simplify complex queries and provide an abstract layer over underlying tables, making data easier to work with.
Suppose you need to calculate the distances between the branches.
The table branches stores information about the locations of the Head Office, and several stores:
Name | Latitude | Longitude
--------------+-------------+-----------
Head Office | 0.0 | 0.0
Store A | 0.0 | 0.0
Store B | 0.0 | 0.0
Store C | 0.0 | 0.0
Store D | 0.0 | 0.0
(5 rows)
To analyze the distances between these locations, you can create a view that calculates the distances between each pair of branches using their latitude and longitude coordinates:
CREATE OR REPLACE VIEW branch_routes AS (
SELECT
b1.name AS office_from,
b2.name AS office_to,
CAST((earth_distance(
ll_to_earth(b1.latitude, b1.longitude),
ll_to_earth(b2.latitude, b2.longitude)
) / 1609.344) AS numeric(10, 2)
) AS distance
FROM branches b1
JOIN branches b2 ON (b1.id != b2.id)
);
Note that this view utilizes the earth_distance and ll_to_earth functions to calculate distances, so the earthdistance and cube modules must be installed.[5]
Once the view is created, you can easily query it to retrieve the distances between any pair of branches:
SELECT * FROM branch_routes;
The output should be something like this:
|Office From | Office To | Distance |
--------------|-----------|----------|
| Head Office | Store A | 2.91 |
| Store A | Store B | 0.64 |
| Store B | Store C | 1.84 |
| Store C | Store D | 2.07 |
(4 rows)
This view simplifies the process of analyzing branch locations by presenting the data in a structured and easily accessible format, eliminating the need to repeatedly write complex SQL calculations.
A sub-query is a query nested within a query. It can be used in SELECT, INSERT, UPDATE or DELETE statements, or even within another subquery, making them versatile tools for performing complex operations within a single query.
Subqueries are particularly useful in scenarios where you need to:
Subqueries can check for the existence of certain rows, and filter data based on related tables. Assume you need a report on products that have had sales on the current date.
Here’s how you can accomplish this using a subquery:
SELECT id, name
FROM products
WHERE EXISTS(
SELECT 1
FROM order_items
WHERE product_id = products.id AND date::DATE = CURRENT_DATE
);
This query returns all products that have one or more order items records for the current day.
Subqueries are used for filtering data by comparing them to aggregated results from another query. Consider generating a report of employees whose age is above the average age.
This can be achieved using a subquery as follows:
SELECT first_name, last_name
FROM employees
WHERE EXTRACT(YEAR FROM AGE(birth_date))::INTEGER > (
SELECT AVG(EXTRACT(YEAR FROM AGE(birth_date)))::INTEGER
FROM employees
);
This subquery calculates the average age of employees, and the outer query filters employees whose age exceeds that average.
Subqueries can also be used for inserting data into a table based on the results of another query. This is useful when you need to separate sensitive data, such as user credentials, from other information.
Suppose you want to add an extra layer of security by migrating sensitive user data from the employees table to a new users table:
INSERT INTO users (email_address, password)
SELECT email_address, password
FROM employees;
After populating the users table, you need to encrypt the data to ensure that sensitive information, like passwords, is stored securely.
Once the data in the users table is securely encrypted, you should delete the corresponding sensitive columns from the employees table to ensure that the information is not stored in multiple locations.
Common table expressions allow you to define temporary result sets that can be referenced within a SELECT, INSERT, UPDATE or DELETE statement.
Using CTEs is a way to simplify complex queries, improve readability, and reduce redundancy by eliminating the need to repeat subqueries or joins.
Imagine you need to generate a report of store managers whose salaries fall between the minimum and average salary:
SELECT e.first_name, e.last_name
FROM employees e
JOIN job_titles t ON (t.employee_id = e.id)
JOIN salaries s ON (s.employee_id = e.id)
WHERE t.description = 'Store Manager'
AND s.amount <= (
SELECT AVG(s.amount) AS avg_salary
FROM employees e
JOIN job_titles t ON (t.employee_id = e.id)
JOIN salaries s ON (s.employee_id = e.id)
WHERE t.description = 'Store Manager'
)
AND s.amount >= (
SELECT MIN(s.amount) AS avg_salary
FROM employees e
JOIN job_titles t ON (t.employee_id = e.id)
JOIN salaries s ON (s.employee_id = e.id)
WHERE t.description = 'Store Manager'
);
While this query is understandable, it involves repeated joins and subqueries that can be streamlined for better readability.
This is where CTEs come into play:
WITH managers AS (
SELECT e.id, e.first_name, e.last_name, s.amount AS salary
FROM employees e
JOIN job_titles t ON (t.employee_id = e.id)
JOIN salaries s ON (s.employee_id = e.id)
WHERE t.description = 'Store Manager'
),
stats AS (
SELECT AVG(salary) AS avg_salary, MIN(salary) AS min_salary
FROM managers
)
SELECT m.first_name, m.last_name
FROM managers m
WHERE m.salary >= (SELECT min_salary FROM stats)
AND m.salary <= (SELECT avg_salary FROM stats);
In this query, the CTEs managers and stats encapsulate the logic for filtering and calculating salaries, which reduces repetition and ensures that subqueries are executed only once.
CTEs also enable the creation of recursive queries.
A recursive CTE is a CTE that refers to itself during execution. It is used to query hierarchical or graphical data, such as a company’s organizational structure or a family tree.
To understand how this works, let’s figure out the workflow of a recursive CTE:
Here’s the general syntax:
WITH RECURSIVE expression_name AS (
-- Anchor member definition
initial_query
UNION ALL
-- Recursive member definition
recursive_query
)
The anchor member is the statement with which the CTE begins. It serves as the starting point of the recursion.
The recursive member is the statement that references the CTE itself. Each iteration uses the result of the previous iteration.
The termination condition is the one that terminates the recursive query in the CTE or else the query may get stuck in an infinite loop, so be careful with that condition, it is essential.
The UNION ALL operator combines the anchor member’s results and the results obtained from all iterations of the recursive member.
To illustrate, let’s use a recursive CTE to find all possible routes from the Head Office, visiting all the branches, and returning to the Head Office:
WITH RECURSIVE possible_routes AS (
SELECT
r.office_to,
r.office_from || ' -> ' || r.office_to AS route,
r.distance AS total_distance,
1 AS depth
FROM branch_routes r
WHERE r.office_from = 'Head Office'
UNION ALL
SELECT
r.office_to,
pr.route || ' -> ' || r.office_to AS route,
(CAST((pr.total_distance + r.distance) AS DECIMAL(10, 2))) AS total_distance,
pr.depth + 1 AS depth
FROM possible_routes pr
JOIN branch_routes r ON (r.office_from = pr.office_to)
WHERE pr.route NOT LIKE ('%' || r.office_to || '%')
)
SELECT
route || ' -> ' || 'Head Office' AS route,
r.total_distance + return_dist.distance AS total_distance
FROM possible_routes r
JOIN branch_routes return_dist ON (return_dist.office_from = r.office_to AND return_dist.office_to = 'Head Office')
WHERE r.depth = 4
ORDER BY total_distance ASC;
The output should be something like this:
Route | Distance
------------------------------------------------------------------------|----------------
Head Office -> Store B -> Store D -> Store A -> Store C -> Head Office | 9.33
Head Office -> Store B -> Store A -> Store C -> Store D -> Head Office | 9.55
Head Office -> Store B -> Store D -> Store C -> Store A -> Head Office | 9.61
Head Office -> Store B -> Store C -> Store A -> Store D -> Head Office | 9.64
Head Office -> Store B -> Store A -> Store D -> Store C -> Head Office | 9.75
Head Office -> Store D -> Store B -> Store A -> Store C -> Head Office | 9.90
Head Office -> Store B -> Store C -> Store D -> Store A -> Head Office | 10.12
Head Office -> Store D -> Store B -> Store C -> Store A -> Head Office | 10.27
Head Office -> Store C -> Store D -> Store B -> Store A -> Head Office | 10.38
Head Office -> Store D -> Store A -> Store B -> Store C -> Head Office | 10.41
Head Office -> Store C -> Store B -> Store D -> Store A -> Head Office | 10.47
Head Office -> Store D -> Store C -> Store B -> Store A -> Head Office | 10.69
(12 rows)
A CASE statement allows you to return results based on the evaluation of specific conditions. It helps make your queries more dynamic by adapting data to various scenarios.
One common and effective use of the CASE statement is Pivoting Data, which rearranges columns and rows to present data from different perspectives.
Let’s say you need to generate a report showing sales grouped by month for the current year.
You can achieve this by using the CASE statement to pivot the data:
SELECT
SUM (CASE WHEN EXTRACT(month from date) = 1 THEN total_paid ELSE 0 END) AS "January",
SUM (CASE WHEN EXTRACT(month from date) = 2 THEN total_paid ELSE 0 END) AS "February",
SUM (CASE WHEN EXTRACT(month from date) = 3 THEN total_paid ELSE 0 END) AS "March",
SUM (CASE WHEN EXTRACT(month from date) = 4 THEN total_paid ELSE 0 END) AS "April",
SUM (CASE WHEN EXTRACT(month from date) = 5 THEN total_paid ELSE 0 END) AS "May",
SUM (CASE WHEN EXTRACT(month from date) = 6 THEN total_paid ELSE 0 END) AS "June",
SUM (CASE WHEN EXTRACT(month from date) = 7 THEN total_paid ELSE 0 END) AS "July",
SUM (CASE WHEN EXTRACT(month from date) = 8 THEN total_paid ELSE 0 END) AS "August"
FROM orders
WHERE date >= '2024-01-01'::DATE;
The output should be something like this:
| January | February | March | April | May | June | July | August |
| -------- | -------- | -------- |-------- |-------- |-------- |---------- |--------|
| 800.00 | 824.00 | 872.00 | 944.00 | 1088.00 | 1276.00 | 1452.00 | 1620.00|
This query effectively pivots the orders data, transforming rows into columns to display monthly sales totals.
Functions allow you to break code into smaller chunks, reducing repetition and enabling code reuse. Imagine you need a report that lists orders along with their totals and statuses.
You might start with a query as follows:
SELECT
id,
total_paid,
CASE
WHEN status = 0
THEN 'Opened'
WHEN status = 1
THEN 'Paid'
WHEN status = 2
THEN 'Canceled'
END AS status_description
FROM orders;
While this query works, it can become repetitive if you need to use the same logic in multiple places. To make your query cleaner and more reusable, you can move the CASE clause into a user-defined function:
CREATE OR REPLACE FUNCTION get_status(status integer)
RETURNS varchar AS $$
BEGIN
RETURN CASE
WHEN status = 0
THEN 'Opened'
WHEN status = 1
THEN 'Paid'
WHEN status = 2
THEN 'Canceled'
END;
END;
$$ LANGUAGE PLPGSQL;
SELECT id, total_paid, get_status(status) AS status_description
FROM orders;
With that function in place, the query becomes simpler and easier to read.
User-defined functions are just one type of function available in SQL. There are many others designed for specific purposes, which we’ll explore next.
Ranking functions are a subset of window function that assign a rank to each row within a partition of a result set, based on a specific order. The most commonly used ranking functions are ROW_NUMBER(), RANK(), and DENSE_RANK().
The RANK() function assigns a rank to each row within a partition, assigning the same rank to rows with identical values. However, the next rank is incremented by the number of tied rows, resulting in gaps in the ranking sequence.
Picture a situation where you rank employees by their salaries, where the highest salary receiving the top rank.
Here’s how the RANK() function can be utilized to reach this:
SELECT
e.id,
s.amount,
RANK() OVER (ORDER BY s.amount DESC) AS rank
FROM employees e
JOIN salaries s ON (s.employee_id = e.id);
If the salaries were 100, 100, and 50, the ranks would be 1, 1, and 3.
The DENSE_RANK() function is similar to RANK() but it does not produce gaps in the ranking sequence. Rows with same values receive the same rank, and the next rank is incremented by one.
Now, consider ranking employees based on their salaries, ensuring there are no gaps in the ranking.
This can be done using the DENSE_RANK() function:
SELECT
e.id,
s.amount,
DENSE_RANK() OVER (ORDER BY s.amount DESC) AS dense_rank
FROM employees e
JOIN salaries s ON (s.employee_id = e.id);
If the salaries were 200, 200, and 50, the ranks would be 1, 1, and 2.
The ROW_NUMBER() function assigns a unique sequential integer to each row within a partition of the result set. Unlike the other functions, it ignores ties and always increments by one for each row.
Imagine you need to rank employees by their salaries, assigning a unique number to each employee.
Here’s the approach using the ROW_NUMBER() function:
SELECT
e.id,
s.amount,
ROW_NUMBER() OVER (ORDER BY s.amount DESC) AS row_num
FROM employees e
JOIN salaries s ON (s.employee_id = e.id);
If the salaries were 100, 100, and 50, the ranks would be 1, 2, and 3.
Ranking is a common application. When it is required to make this on the data, using SQL for such purpose, will reduce the amount of data transferred and the complexity of the application logic.
An index is a quick lookup table that allows the database to locate data efficiently without having to search every row in a table each time it’s accessed.
The most common type of index used in SQL databases is the B-tree.
Let’s dive deeper into B-tree Indexing.
A B-tree is a tree data structure that allows logarithmically amortized searches, inserts, and deletes while sorting the data. Once the B-tree index is created, it is automatically maintained by the database. Each insert, delete, and update is applied to the index, and the balanced tree is preserved, which generates a maintenance overhead for write operations.
Each node has a key, a pointer referring to the actual record on disk, and a pointer referring to the child node.

When querying a B-tree, the process starts at the root node of the tree and compares the value of the requested data with the keys stored at the current node. If the requested data is less than the key value, the search continues at the left child of the current node. If the requested data is greater than the key value, the search continues on the right child of the current node. This process is repeated recursively until the requested data is found or it is determined that the data is not present in the tree.
Let’s see what happens when the following query is executed:
SELECT * FROM employees WHERE identifier = '0014';

Without an index, database engines perform a full table scan, which means that it starts at the first row of the table and checks each row sequentially until it finds a match or reaches the end of the table.
After exploring the history and syntax of SQL, it is clear that the language was designed to provide a powerful and intuitive way to manage and access data. A comprehensive understanding of its syntax, from basic commands to advanced functionalities, is essential for effectively working with data and deriving meaningful insights.