Book a Free Call
No commitment required

We live in a time where accessing information is easier than ever. The advent of the Internet and the increase of digital devices has transformed how we collect, share, and consume data. From breaking news and weather updates to academic research and streaming entertainment, the world’s knowledge is now at our fingertips, accessible anytime and anywhere.
Despite the incredible amount of information we consume daily, it represents just a fraction of the Internet. There is a hidden realm you might have heard off: the Dark Web. This post will explore the ‘Dark side of the Internet’ and how is related to the Tor project.
Estimating the total amount of data available on the web is nearly impossible. Millions of servers worldwide host vast information, creating an extensive and ever-growing digital landscape.
Browsers serve as the gateways to this wealth of information. Popular browsers like Google Chrome, Firefox, and Safari enable users to access the web through intuitive graphical interfaces on desktop and mobile devices. Additionally, libraries in various programming languages allow programmatic access to these tools, opening up a whole new world of possibilities for building custom applications.
The Internet is a never-ending world divided into three sections. Each section requires a different strategy to access the Web. Before we dig deeper into this world, we need to understand these differences, so let’s use the “iceberg” diagram to illustrate them at a high level:

Taken from: Dark Web vs. Deep Web: 5 Key Differences
What we see from the surface is known as the Surface Web, which we know as the regular web. On this side of the Internet, we carry out daily activities such as searching for data, shopping online, visiting social networks, reading posts on Wawandco, etc.
All the pages you get from using browsers like Google Chrome, Firefox, or Safari and a search engine like Google are indexed; that is, they are available to be found by the public without any security restrictions. Information such as our IP address may also be identified when we visit one of these sites.
A browser is a piece of software that retrieves and displays web pages; A search engine is a web service that helps people find web pages from other websites. [1]
Let’s continue with the iceberg analogy. The underwater part comprises the deep web and the dark web. The estimated amount of information we can find on the Deep Web is considerably more significant than the “visible web” or “surface web.” The reason is that the content of the Deep Web ranges from personal information (cloud data, personal data of any organization or military data) to financial records, academic databases, legal files, medical records, network profile information, social and scientific, and governmental records.
All the information mentioned above is not indexed; they are not visible to search engines. Therefore, to access data within the deep web, you need access credentials or special authorization. Think of it as private data kept under lock and key. For example, if someone tried to search for your email password on Google, they would have no results because it is in a database. Another example of content within the deep web would be an organization’s private network. If you tried to use Google to search for internal data of that organization, you wouldn’t get any results either because search engines cannot crawl it.[2]
Finally, we have the dark side of the Internet. Sometimes, people use the terms Deep Web and Dark Web interchangeably, which is incorrect since the Dark Web is an even smaller portion of the Internet. It is a subset of the Deep Web. The same cannot be said the other way around.
Pages hosted on the Dark Web are invisible to the general public. They are not indexed, so web crawlers cannot access that information. To that extent, the Dark Web is similar to the Deep Web. The difference is that you need particular software to access information people hide intentionally on the Dark Web. You cannot use typical browsers such as Google Chrome, Firefox, Safari, Edge, etc., to access the Dark Web the same way you would on the Surface or Deep Web.
The main characteristic of the Dark Web is that it offers anonymity to website owners and visitors. It is possible to hide any trace that leads to your identity so that no one can trace your IP address, for example.
The above facilitates illegal activities such as the sale of drugs, the sale of weapons, stolen products, organ trafficking, and the planning of cyber attacks, in addition to the purchase and sale of sensitive information of individuals or organizations. Of course, it is not only used for dark purposes. Some, for example, use this medium to express their ideas on a topic without risking exposing themselves to the outside world. Especially in those places where freedom of speech is limited and there is fear of persecution.[3]
Other interesting uses of the Dark Web are related to cybersecurity. As we discussed, trafficking stolen confidential information is one of many illegal activities that one can find on this side of the Internet. Even with security strategies in place, cyber-attacks or data leaks can affect anyone, so actively seeking information about the Dark Web is a good starting point to mitigate risks.
As previously mentioned, we need dedicated software to access the Dark Web, given that it uses a system for data encryption, among other security strategies, to allow anonymity. For example, this is the URL of a page on the Dark Web: http//:oihqwoiehqoizqwqwher.onion.
Onion sites are pages accessible only through the Tor network, the most popular network on the Dark Web. Let’s see how it works.
The Onion Router project is an open-source initiative designed to help users browse the Internet anonymously. It employs a technique known as onion routing, which encrypts and routes internet traffic through a series of nodes worldwide (relays and servers). It resembles layers of an onion and ensures that your identity and activities remain hidden from prying eyes. Using the Tor network has two main properties:
Your internet service provider and anyone locally watching your connection cannot track your internet activity, including the names and addresses of the websites you visit.
The operators of the websites and services you use, and anyone watching them, will see a connection coming from the Tor network instead of your actual Internet (IP) address and will only know who you are if you explicitly identify yourself. [4]
The Tor network uses three layers of nodes that resemble layers of an onion. The layers play the role of Tor servers or routers, making it difficult to track your fingerprints. Let’s think of it as a circuit:
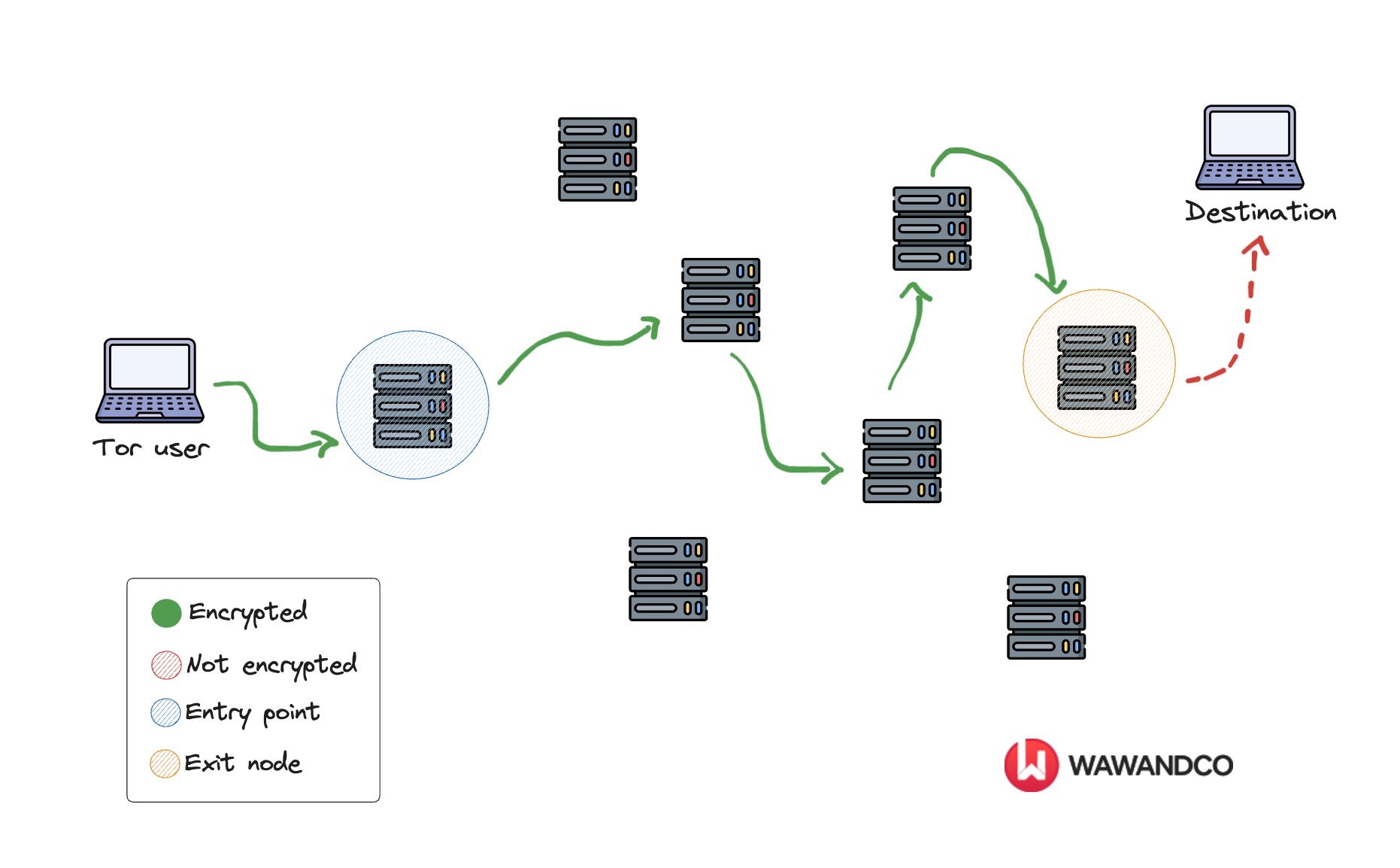
When a Tor user starts a new connection, Tor randomly chooses an entry point (or entry guard) to encrypt their data and introduce them into the Tor circuit. The entry guard must be stable and fast (at least 2MByte/s of upstream and downstream bandwidth) and establish the encryption key of the following relay node.
Your data transits through several middle nodes, also called relay nodes. These nodes only know the encryption key of the previous and following nodes in the circuit and do not have access to the complete traffic. Each of the middle nodes decrypts a layer of encryption and forwards the data to the next relay node.
Finally, the last node (the exit relay) completes the Tor circuit, removing the final layer of encryption and sending the data to its destination. The services Tor clients are connecting to (website, chat service, email provider, etc.) will see the IP address of the exit relay instead of the actual IP address of the Tor user.[5]
As we learned, we can find a whole ocean of information on the internet. While the Surface Web is easily accessible and contains information that is indexed and readily available through search engines, the Deep Web holds a wealth of valuable but private information, such as personal and financial records, academic databases, and legal files.
On the other hand, it’s important to remember that while the Dark Web is often portrayed in a negative light due to its association with illegal activities, it also serves as a platform for those who want to add a layer of security to their data by using cybersecurity strategies.
Understanding the distinctions between these layers of the internet it’s essential to approach each with caution and responsibility. Whether it’s for research, cybersecurity, or simply out of curiosity, it’s important to navigate the internet with an awareness of its complexities and the potential risks and opportunities it presents.
That’s a wrap! We saw how the Tor project opens the door to a new world by leveraging different techniques to provide anonymity to its users. However, we covered only the theory. It’s worth exploring how to access the ‘Dark side of the Internet.’ The good news is that for our next post, we’ll see different ways to connect to the Tor project. So, stay tuned!