Book a Free Call
No commitment required
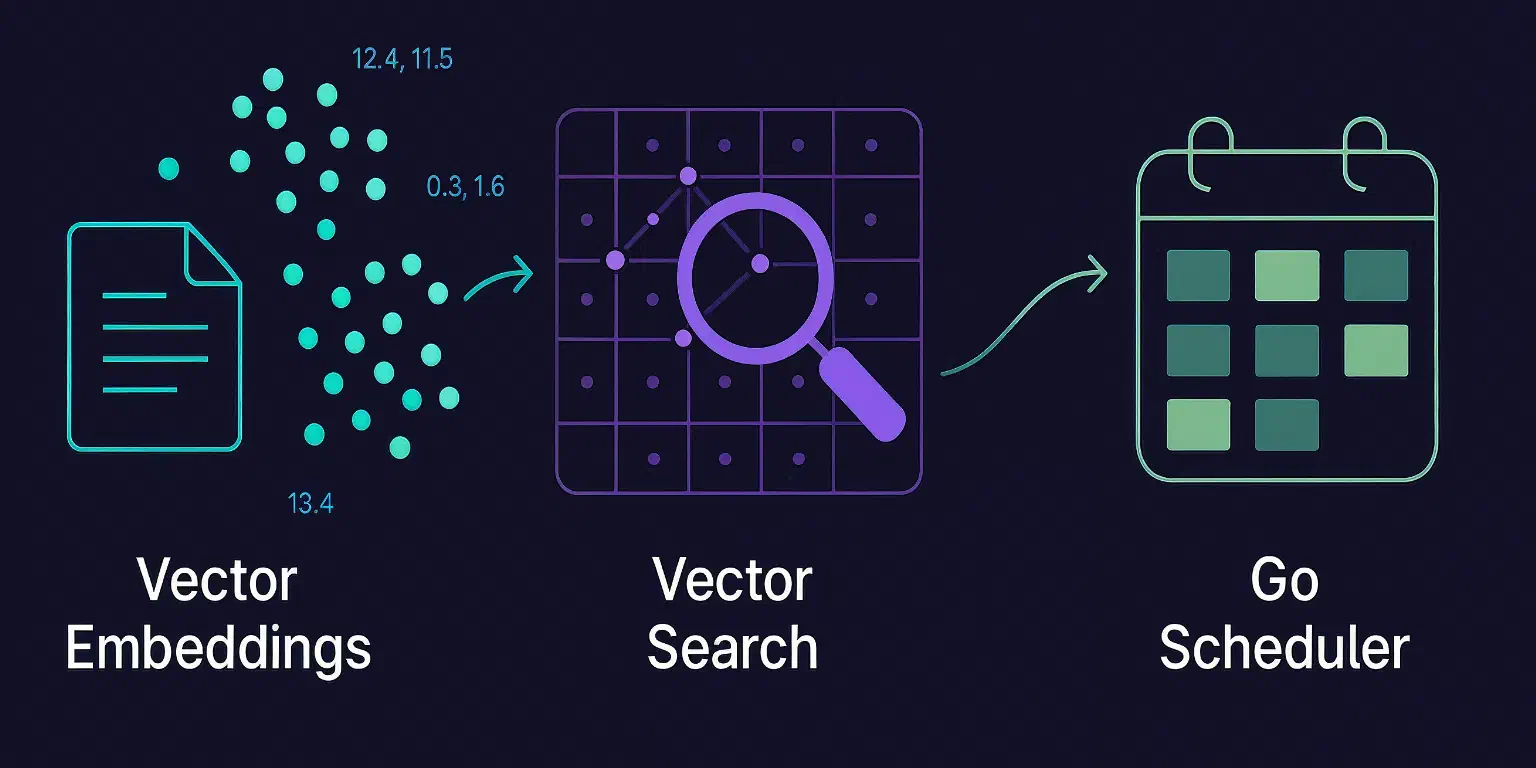
TL;DR: We reduced response times from 5 minutes to 5 seconds (98% reduction) by switching from an LLM-only architecture to a vector search + Go scheduler approach. The key insight: not every problem needs LLM reasoning. By using pgvector for semantic matching and Go for deterministic scheduling, we achieved better performance, lower costs, and more consistent results for Symbol Security’s training program generation.
Key Results:
Last updated: March 2026
Artificial intelligence is versatile, and that versatility leads many teams to reach for it by default. Large Language Models can handle complex reasoning, generate creative content, and adapt to countless use cases. This flexibility makes them appealing—sometimes too appealing.
We built an AI system that provided good results, but over time it became a performance problem. Response times stretched to five minutes per request. Users complained. Costs climbed with every call. The natural response would be optimizing the model, tuning prompts, or adding more compute power.
Instead, we asked a different question: were we using the right kind of AI? This post walks through how we reduced response time from five minutes to five seconds—not by making our AI smarter, but by recognizing which parts of the problem actually needed artificial intelligence in the first place.
Working with Symbol Security, we needed to generate customized security awareness programs at scale. The system had to select relevant training assets from hundreds of options, understand business rules, schedule content appropriately, and structure complete programs tailored to each company’s needs.
Our first architecture used a Large Language Model for everything. It worked, but the model processed massive amounts of information in one go, taking around five minutes in production. Waiting that long frustrated users, and complaints started rolling in.
The cost picture looked worse. While each individual request was manageable, the economics didn’t scale. Every long, reasoning-heavy LLM call added up. As the customer base grew, infrastructure costs would grow exponentially. Research shows that LLM latency and cost management become critical bottlenecks as applications scale beyond prototypes.
The solution wouldn’t come from making our AI smarter. It would come from understanding what kind of intelligence the problem required.
We didn’t find the answer immediately. The path took three distinct iterations:
Attempt 1 - LLM-Only: The model handled everything—asset selection, scheduling, program structure. Response time hovered around 2 minutes 30 seconds. The model sometimes produced unpredictable results that broke validation logic.
Attempt 2 - Hybrid (Vectors + LLM): We used vector embeddings to pre-filter assets before passing them to the LLM. Response time improved slightly to around 2 minutes, but the LLM was still doing too much work. Scheduling remained a bottleneck.
Attempt 3 - Vector Search + Go Scheduler: We separated the work completely. Semantic search handled content matching. A deterministic Go scheduler handled the arrangement. Response time dropped to 5 seconds. Fast and consistent.
The key realization was simple: generating a security awareness program doesn’t require creative reasoning. It requires fast, consistent matching.

To see how this works, consider a game called Semantle. You’re trying to guess a secret word. With each guess, the game tells you how semantically similar your guess is to the target—not based on spelling, but on meaning. “Fish” and “seafood” score as very similar even though they share no letters, because AI models trained on massive amounts of text learn that these words appear in similar contexts.
Vector embeddings make this possible. Every piece of text—whether a training asset description or a company’s requirements—converts into a vector: an array of numbers capturing its semantic meaning. In this high-dimensional space, similar concepts cluster naturally. You can query this space using natural language and get semantically relevant matches in milliseconds.
The system needs to take a company’s requirements (industry vertical, compliance needs, employee roles) and match them to relevant training assets. Then arrange those assets into a coherent schedule. The matching needs semantic search capabilities—understanding that “healthcare compliance” relates to “HIPAA training” without exact word matches—but it doesn’t need an LLM’s full reasoning capabilities.
Our redesigned system works in two phases:
Offline (happens once): We convert every training asset into a vector embedding using Google’s Gemini Embedding model. These embeddings are stored in a PostgreSQL database using the pgvector extension, which adds vector similarity search to PostgreSQL’s existing infrastructure.
Online (happens per request): 1.Convert the company’s preferences into a query vector 2.Use semantic similarity search to retrieve the most relevant training assets (under 5 seconds) 3.Pass those assets to a deterministic Go scheduler that arranges them according to scheduling preferences and business rules
The division of labor is clear: vector search handles semantic intelligence (what content is relevant), while the Go scheduler handles deterministic logic (how to arrange that content). Neither task needs an LLM’s heavyweight reasoning.
The diagram below shows the complete system architecture and data flow:

Let’s walk through what happens when a request comes in:
Request Entry Point The process starts with a company’s preferences and ID entering the Go application context. A background worker (GenerateProgramHandler) orchestrates the entire flow, ensuring the process doesn’t block other operations.
Building the Query The Vector Searcher Logic takes the company’s requirements—industry vertical, size, compliance needs—and constructs a natural language query. This isn’t just concatenating fields; it creates meaningful text that captures what the company actually needs. For example: “healthcare organization with 500 employees requiring HIPAA compliance training.”
Embedding the Query This natural language query gets sent to Google’s Gemini API (specifically the text-embedding-001 model), which converts it into a vector—an array of numbers representing the semantic meaning of the request.
Hybrid Vector Search Here’s where the system gets interesting. The search isn’t purely semantic—it’s hybrid. The query vector searches the asset_embeddings table (using pgvector’s similarity functions) to find training assets with similar semantic meaning. But it also applies filters: checking which assets the company’s subscription includes, which providers they have access to, and other business logic constraints. This returns a list of relevant asset UUIDs.
Retrieving Complete Asset Data Those UUIDs get passed to standard relational tables containing the full asset details—courses, templates, subscriptions, and library assets. This separation is intentional: embeddings handle semantic search, while relational tables handle structured data and relationships.
Deterministic Scheduling The Scheduler Algorithm receives the filtered, relevant assets and maps them to months according to the company’s calendar preferences, training frequency requirements, and scheduling rules. This is pure Go code—no AI, just logic. It ensures consistent, predictable program structures.
Return Results The complete program—with assets selected semantically and arranged logically—returns to the handler, which delivers it to the user.
At first glance, the diagram might look complex. But each component does exactly one thing:
PostgreSQL does double duty efficiently. The same database handles both vector similarity search (via pgvector) and traditional relational data. No need for separate vector databases, graph databases, or specialized infrastructure. One system, two capabilities, properly indexed for each use case.
Each layer has clear responsibilities. The vector search layer doesn’t schedule. The scheduler doesn’t search. The background worker doesn’t make business logic decisions—it just coordinates. When components have single, well-defined purposes, they’re easier to test, debug, and maintain.
The system scales naturally. Need more capacity? Add database replicas. Need faster embeddings? Batch them or cache them. Need different scheduling rules? Modify one algorithm. Each scaling decision is independent because the concerns are separated.
External dependencies are minimal. The only external service is Google’s embedding API, and it’s only called once during the offline embedding generation phase (or when new assets are added). Everything else runs on infrastructure you control.
This architecture demonstrates that simplicity is about ensuring each component has a clear job and the relationships between them are straightforward. The data flows in one direction. There are no circular dependencies. Each piece can be understood in isolation.
Compare this to the original LLM-only approach, where a single model tried to handle semantic understanding, business logic, scheduling constraints, and output formatting all at once. That’s not simpler—it’s just fewer boxes on a diagram.
The numbers:
The system currently handles up to 100,000-150,000 vector records with the current indexing strategy. If more capacity is needed, additional indexing options are available.
By moving away from LLMs, we gave up some “creative” capabilities. An LLM might generate novel combinations of training content or craft unique program descriptions. Our vector-first system is more predictable and structured.
That predictability is exactly what the use case required. Clients need reliability, speed, and compliance—not creativity in how programs are assembled. The system delivers customized programs, just not creatively customized ones.
There’s also an operational consideration: vector search accuracy depends on the quality of asset descriptions. The team must maintain clear, well-tagged descriptions for each training asset. Poor descriptions reduce search accuracy. But this work improves the entire content library, not just the AI system.
This project revealed several lessons about AI implementation:
Question your assumptions. Just because LLMs can solve a problem doesn’t mean they should. Evaluate whether your use case requires the full capabilities of a language model.
Understand the problem deeply. Program generation was really two separate problems: semantic matching and deterministic scheduling. Breaking it apart revealed simpler solutions.
Measure what matters. We optimized for user experience and operational cost, not “most advanced AI.” Those metrics pointed toward a simpler architecture.
Combine technologies thoughtfully. The final solution uses vector embeddings, PostgreSQL, and Go scheduling logic—each doing what it does best. Effectiveness matters more than using a single elegant approach.
Plan for scale. The vector-first architecture performs better today and scales more economically as the customer base grows.
The AI landscape often treats LLMs as universal solutions. They’re remarkably versatile, and that versatility leads many teams to reach for them by default. LLMs excel at tasks requiring creative reasoning, nuanced language generation, and complex decision-making under uncertainty. When your problem is about fast semantic matching and deterministic logic, different tools work better.
Vector embeddings aren’t new—they’ve existed for years in various forms. What’s changed is the infrastructure. Extensions like pgvector bring vector similarity search into mainstream databases like PostgreSQL, eliminating the need for specialized vector databases. You can build sophisticated semantic search systems using tools you already know and run.
Clients now get their customized training programs in seconds instead of minutes. They don’t know or care about the underlying architecture—they just know it works. The best technology disappears into the background, delivering what users wanted all along: results.
Wawandco Engineering Team — We’ve been shipping production Go applications for 12+ years, specializing in high-performance backends, AI integration, and database optimization. This case study is based on real work with Symbol Security to scale their security awareness training platform.
Questions about vector search or AI architecture? Contact our team or connect with us on LinkedIn.